Professor Kai Chen received his Ph.D. degree in the University of Chinese Academy of Science in 2010; then he joined the Chinese Academy of Science in January 2010. He became the Associate Professor in September 2012 and became the full Professor in October 2015.
His research interests include LLM Security, Software and System Security, AI Security, Privacy Protection.

Selected Interesting Tools

Vulnerability Rule Database (漏洞规则库) [Click to try!]
The Vulnerability Rule Database is a curated collection of code security patterns distilled from large-scale code, docs, and patches via program analysis and Large Language Models (LLMs). Our rules have enabled open-source tools to find over 1,000 defects in popular software.
Selected Interesting Papers
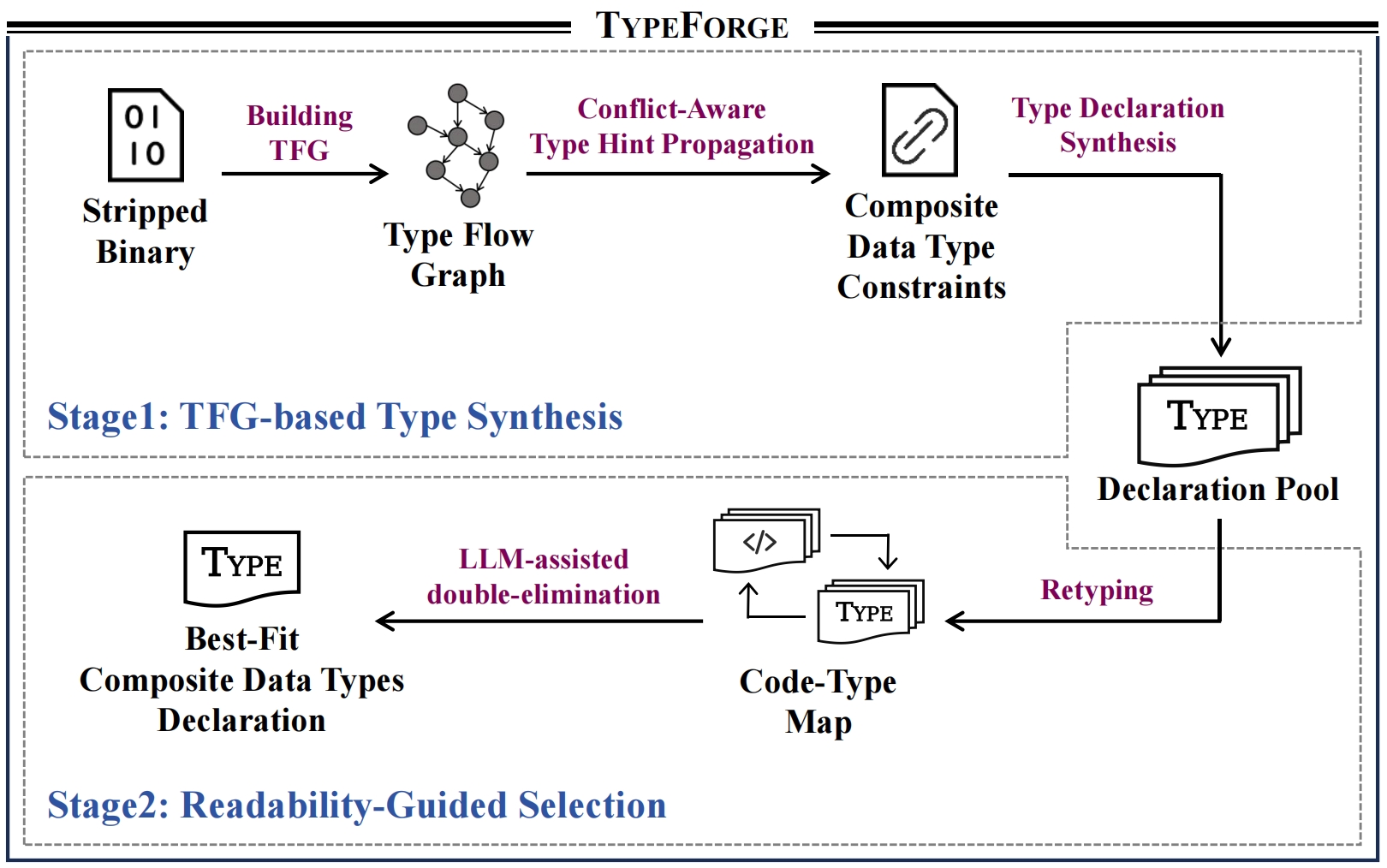
[S&P 2025] TypeForge: Synthesizing and Selecting Best-Fit Composite Data Types for Stripped Binaries
Static binary analysis is a widely used approach for ensuring the security of closed-source software. However, the absence of type information in stripped binaries, particularly for composite data types, poses significant challenges for both static analyzers and reverse engineering experts in achieving efficient and accurate analysis. In this paper, we present TypeForge, a novel approach inspired by the workflow of reverse engineering experts, which uses a two-stage synthesis selection strategy to automate the recovery of composite data types from stripped binaries. Our comparison with state-of-the-art approaches demonstrates that TypeForge achieves F1 scores of 81.7% and 88.2% in Composite Data Type Identification and Layout Recovery, respectively, substantially outperforming existing methods, making it a promising solution for various real-world reverse engineering tasks. [PDF] [CODE]
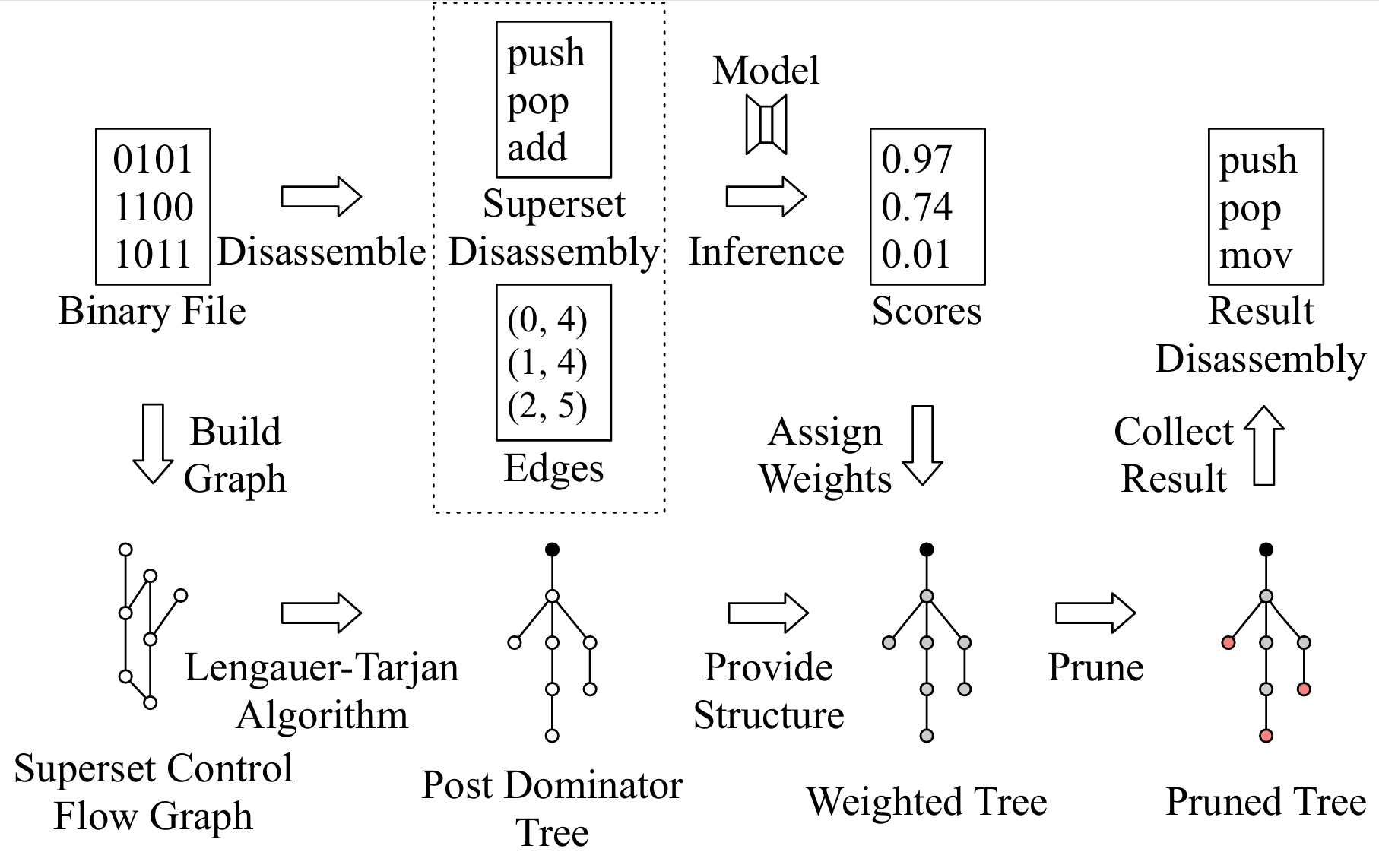
[USENIX Security 2025] Tady: A Neural Disassembler without Structural Constraint Violations
While emerging neural disassemblers show promise for efficiency and accuracy, they frequently generate outputs violating fundamental structural constraints, which significantly compromise their practical usability. We regularize the disassembly solution space by applying key structural constraints based on post-dominance relations. This approach systematically detects widespread errors in existing neural disassemblers' outputs. We introduce Tady, a novel neural disassembler featuring an improved model architecture and a dedicated post-processing algorithm, specifically engineered to address these deficiencies. Comprehensive evaluations on diverse binaries demonstrate that Tady effectively eliminates structural constraint violations and functions with high efficiency, while maintaining instruction-level accuracy. [CODE]
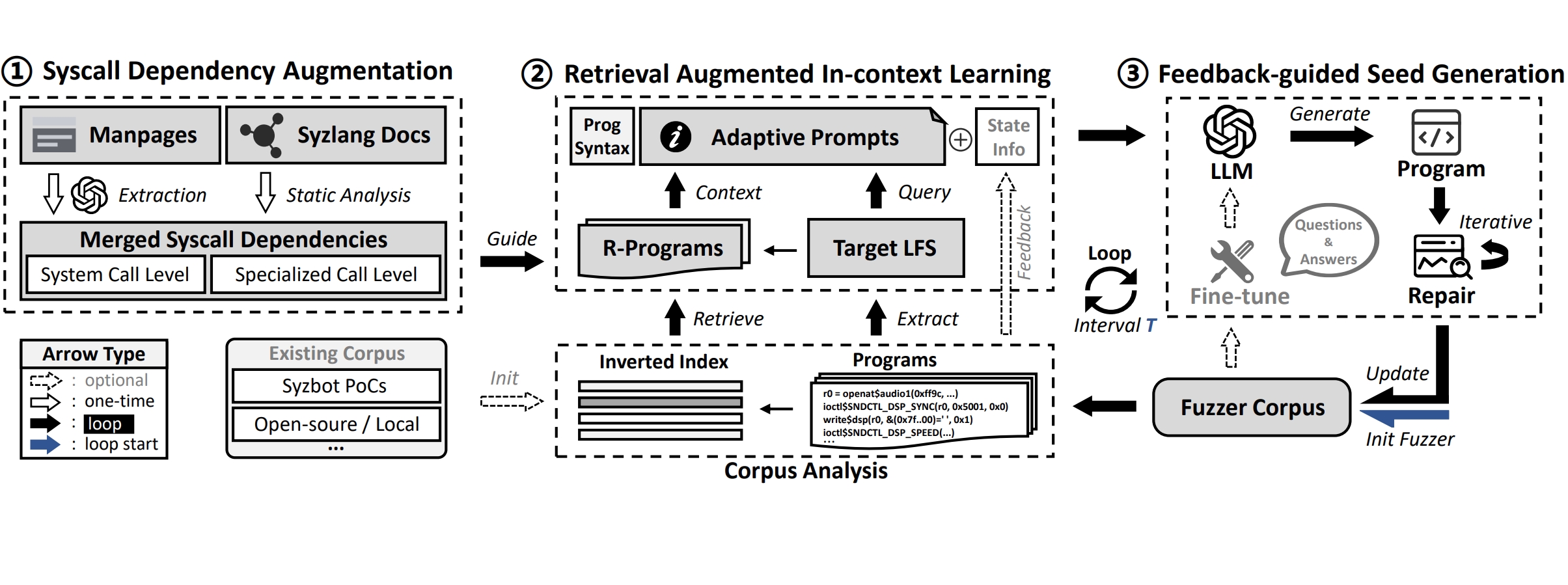
[ISSTA 2025] Unlocking Low Frequency Syscalls in Kernel Fuzzing with Dependency-Based RAG
SyzGPT is the first kernel fuzzing framework that leverages Large Language Models (LLMs) to automatically generate effective seeds for low-frequency syscalls (LFS), which are often missed by coverage-guided fuzzers due to complex dependencies and mutation uncertainty. To address this, we propose a dependency-based retrieval-augmented generation (DRAG) method, which extracts syscall dependencies from documentation via LLM, retrieves context programs from the corpus, and generates & repairs seeds with feedback to enrich LFS-related coverage. SyzGPT achieves a high valid rate (87.84%), and outperforms seven state-of-the-art fuzzers by 17.73% in code coverage, 58.00% in LFS coverage, and 323.22% in vulnerability detection. It also independently discovered 26 new kernel bugs, including 10 LFS-related and 11 confirmed. [PDF] [CODE]
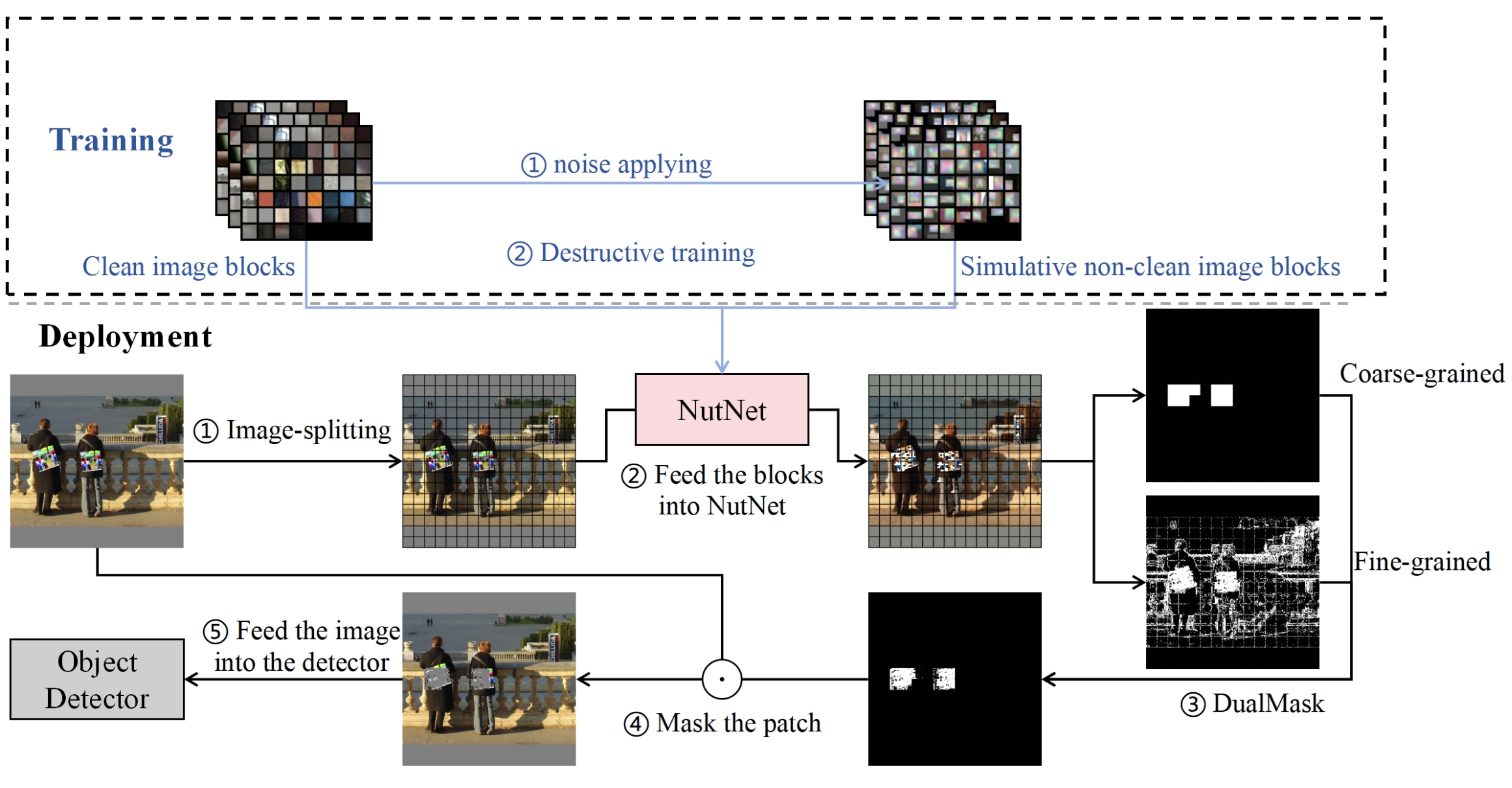
[CCS 2024] I Don't Know You, But I Can Catch You: Real-Time Defense against Diverse Adversarial Patches for Object Detectors
We propose NutNet, a comprehensive defense that effectively defends against both Hiding Attacks and Appearing Attacks without incurring significant computational overhead. NutNet can effectively locate and mitigate the adversarial patches in the image and can be integrated as a data-preprocessing module into any pre-trained detector without requiring modifications to the original architecture. We conduct extensive experiments in both the digital and physical world to validate the effectiveness of NutNet in defending six detection models, i.e., one-stage detectors (YOLO V2-V4, SSD), two-stage detectors (Faster RCNN) and transformer-based detectors (DETR). [PDF] [CODE] [DEMO]
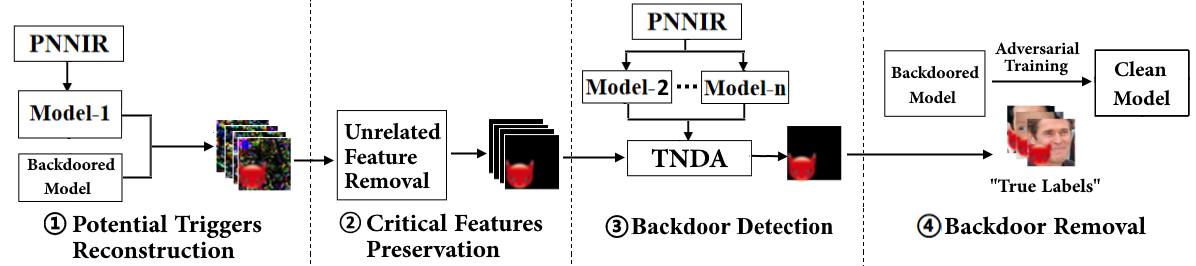
[TIFS 2024] NeuralSanitizer: Detecting Backdoors in Neural Networks
In this paper, we propose NeuralSanitizer, a novel approach to detect and remove backdoors in DNNs, capable of capturing various triggers with better accuracy and higher efficiency. In particular, we identify two fundamental properties of triggers, i.e., their effectiveness in the backdoored model and ineffectiveness in other clean models, and design a novel objective function to reconstruct triggers based on them. Then we present a new approach that leverages transferability to identify adversarial patches that could be generated during trigger reconstruction, thus detecting backdoors more accurately. We evaluate NeuralSanitizer on real-world backdoored DNNs and achieve 2.1% FNR and 0.9% FPR on average, significantly outperforming the state-of-the-art works by 1∼14 times. In addition, NeuralSanitizer can reconstruct triggers up to 25% of the size of the original inputs on average, compared to only 6∼10% by existing works. Finally, NeuralSanitizer is also 1∼25 times faster than existing works. [CODE]
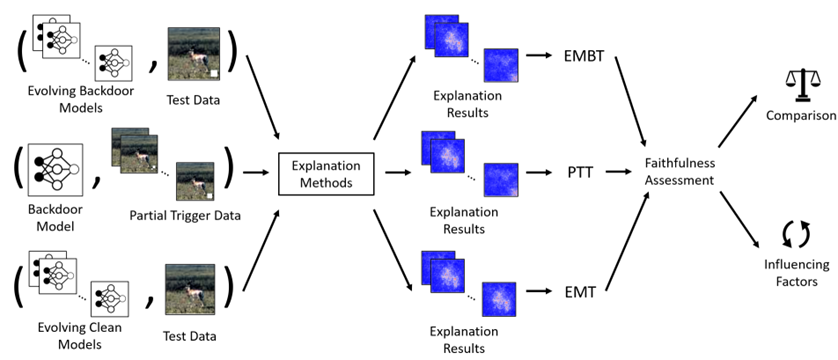
[CCS 2023] Good-looking but Lacking Faithfulness: Understanding Local Explanation Methods through Trend-based Testing
We evaluate the faithfulness of explanation methods and find that traditional tests on faithfulness encounter the random dominance problem, ie, the random selection performs the best, especially for complex data. To further solve this problem, we propose three trend-based faithfulness tests and empirically demonstrate that the new trend tests can better assess faithfulness than traditional tests on image, natural language and security tasks. We implement the assessment system and evaluate ten popular explanation methods. Benefiting from the trend tests, we successfully assess the explanation methods on complex data for the first time, bringing unprecedented discoveries and inspiring future research. Downstream tasks also greatly benefit from the tests. For example, model debugging equipped with faithful explanation methods performs much better for detecting and correcting accuracy and security problems. [PDF] [CODE]
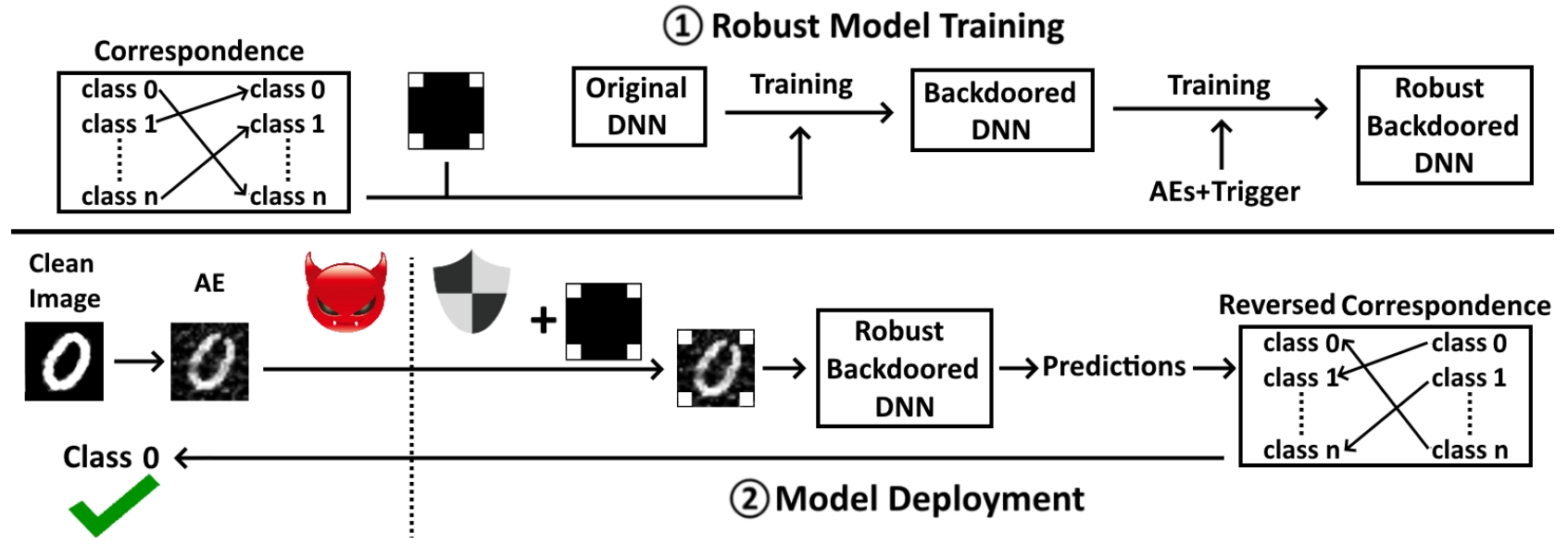
[S&P 2023] AI-Guardian: Defeating Adversarial Attacks using Backdoors
We present AI-Guardian, a novel approach to defeating adversarial attacks that leverages intentionally embedded backdoors. We design a unique backdoor, called bijection backdoor, to change the behavior of the protected model, mitigating the impact of adversarial examples on the final outputs without affecting the model's performance on the original tasks. We conduct extensive evaluation and experimental results show that AI-Guardian reduces the attack success rate from 97.3% to 3.2%, with only a 0.9% decline on the clean data accuracy. Furthermore, AI-Guardian introduces only 0.36% overhead to the model prediction time, almost negligible in most cases. [PDF] [CODE]
[USENIX Security 2023] AURC: Detecting Errors in Program Code and Documentation
We present AURC, a static framework for detecting code bugs of incorrect return checks and document defects. We observe that three objects participate in the API invocation, the document, the caller (code that invokes API), and the callee (the source code of API). Mutual corroboration of these three objects boosts the detection of code and documentation errors. We evaluated AURC on ten popular codebases. AURC discovered 529 new bugs and 224 new document defects. Maintainers acknowledge our findings and have accepted 222 code patches and 76 document patches. [PDF] [CODE]
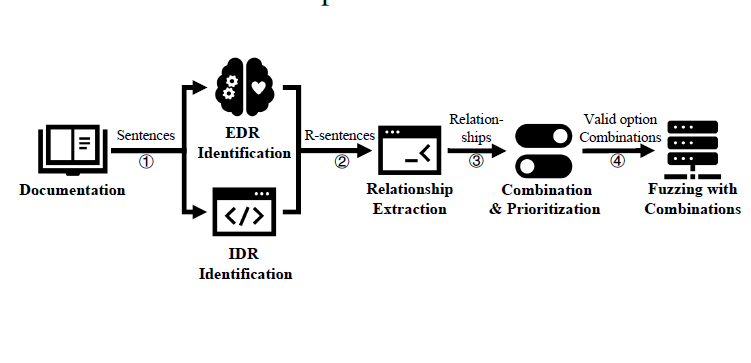
[USENIX Security 2023] CarpetFuzz: Automatic Program Option Constraint Extraction from Documentation for Fuzzing
We proposed a novel technique for identifying and extracting constraints among program options from the documentation. To the best of our knowledge, this is the first study that tries to use NLP to automatically figure out the relationships among program options from the documentation. With the help of this technique, AFL finds 45.97% more paths that other fuzzers cannot discover. We implemented the prototype tool, CarpetFuzz, and evaluated it on 20 popular real-world open-source programs. CarpetFuzz accurately extracted 88.85% of the relationships from their documents. Through fuzzing these programs with the valid option combinations obtained by CarpetFuzz, 57 unique crashes have been found, 30 of which have been assigned with CVE IDs. [PDF] [CODE]
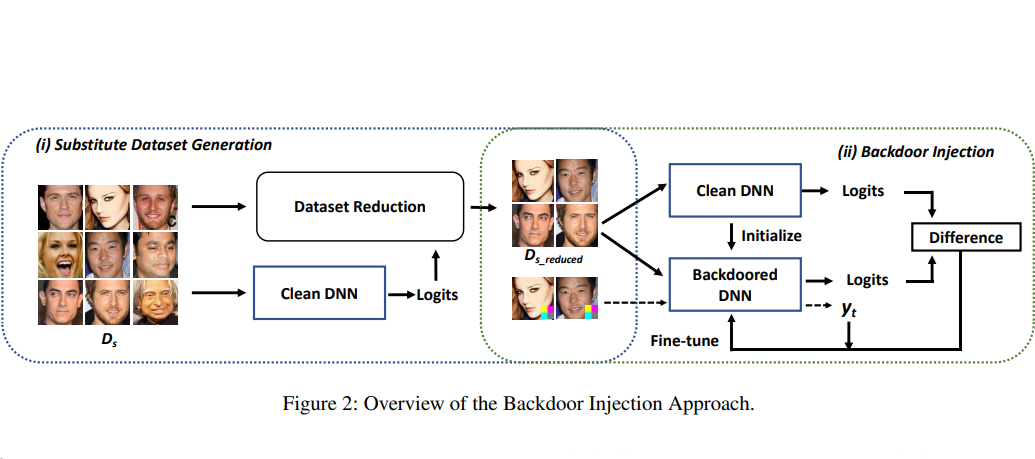
[USENIX Security 2023] A Data-free Backdoor Injection Approach in Neural Networks
We propose a novel backdoor injection approach in a "data-free" manner. We design a novel loss function for fine-tuning the original model into the backdoored one using the substitute data that is irrelevant to the main task, and optimize the fine-tuning to balance the backdoor injection and the performance on the main task. We conduct extensive experiments on various deep learning scenarios, and the evaluation results demonstrate that our data-free backdoor injection approach can efficiently embed backdoors with a nearly 100% attack success rate. [PDF] [CODE]